Source code / Repo:
https://github.com/joshuatz/music-meta-dom-scraper
Description:
There is not a whole lot to this project, and I don’t really have plans to expand on its capabilities, but given how much use I get out of it, I thought it warranted a quick write-up and project page.
The “Music Meta DOM Scraper” is just a bit of Javascript that lets me quickly grab song meta information (track title, artist, release date, etc.) from a few different sources. Right now, those are just Bing search results and AllMusic discography pages.
It does not use any APIs or offer bulk functionality beyond scraping an album at a time; its main purpose is to just clean up the data on the webpage, normalize it a little, and make it easy to copy into my clipboard, so I can then paste it into my catalog tracker of choice (Google Sheets, SQL table, etc.).
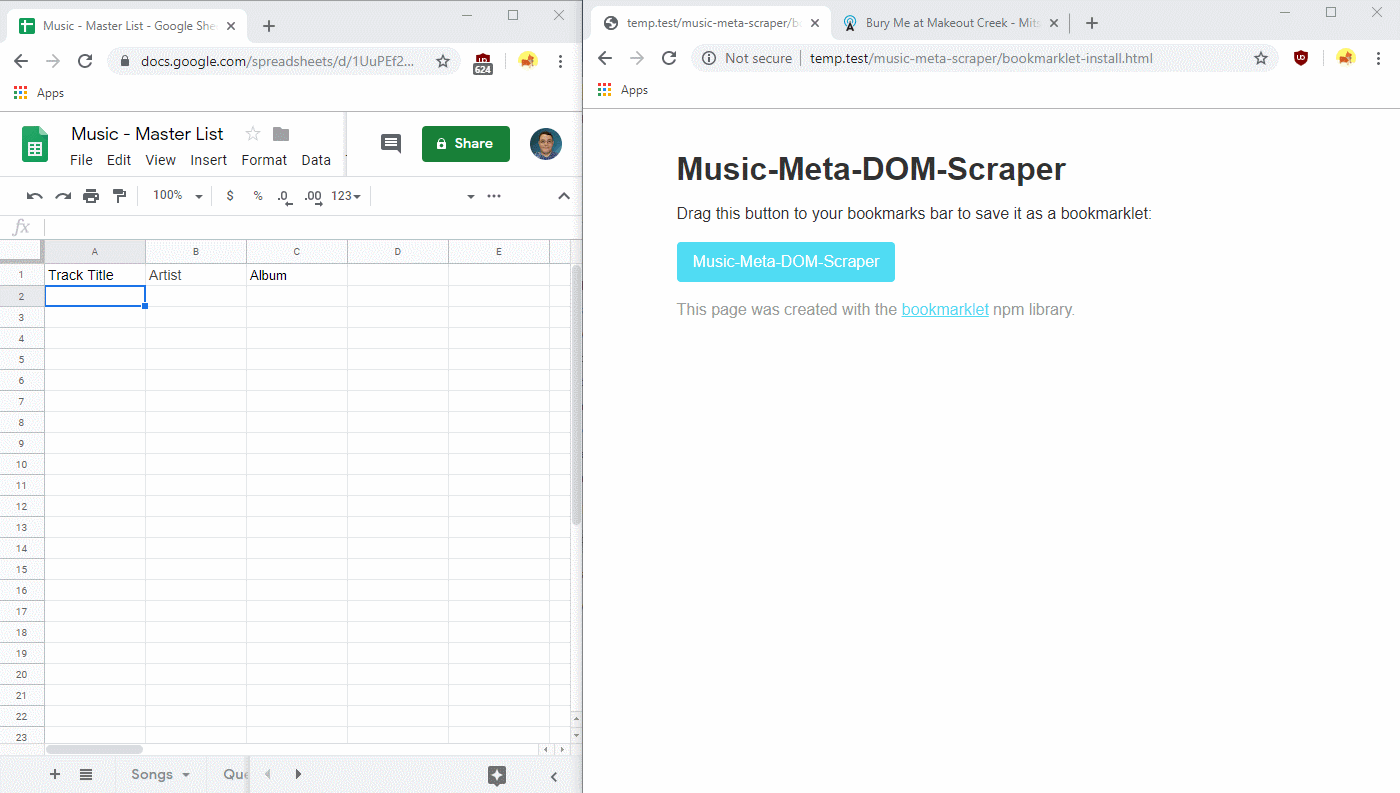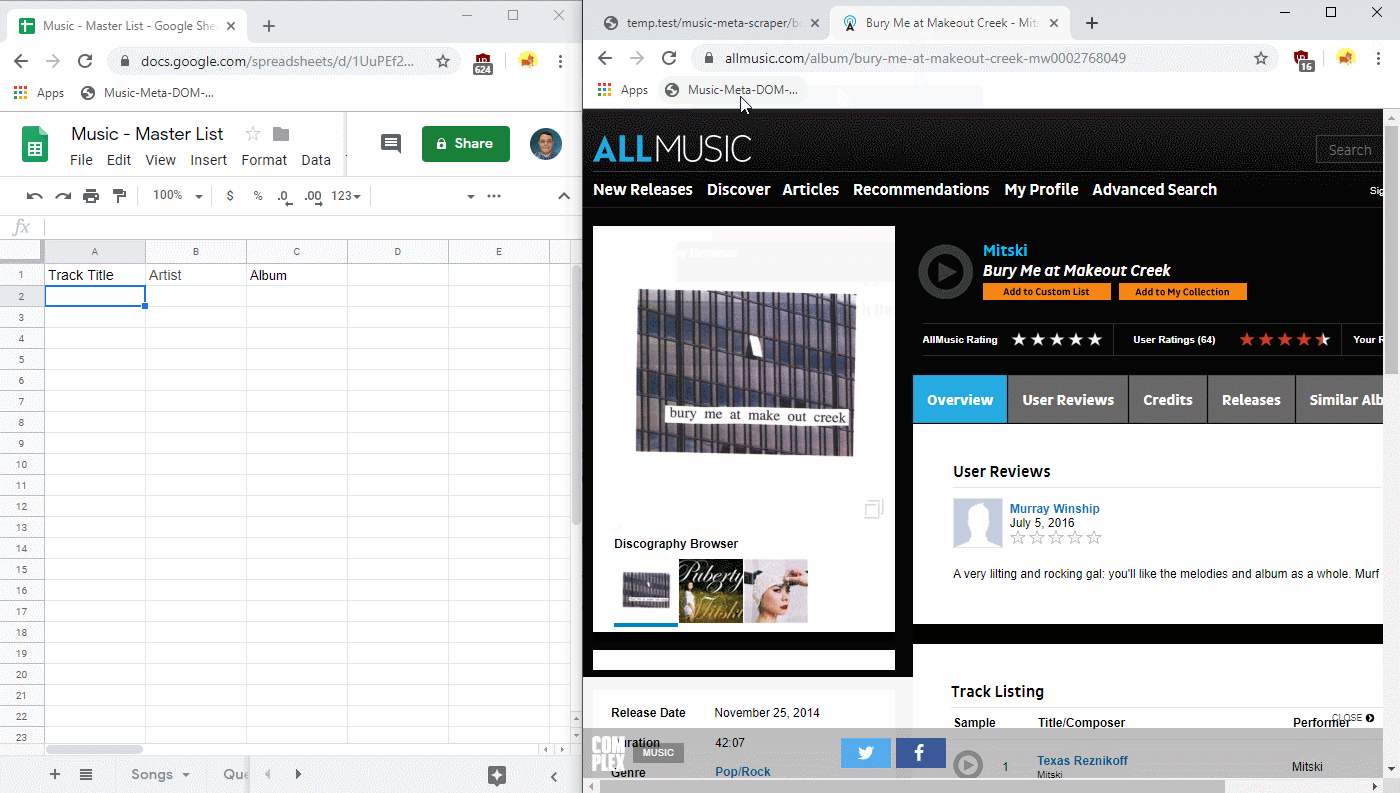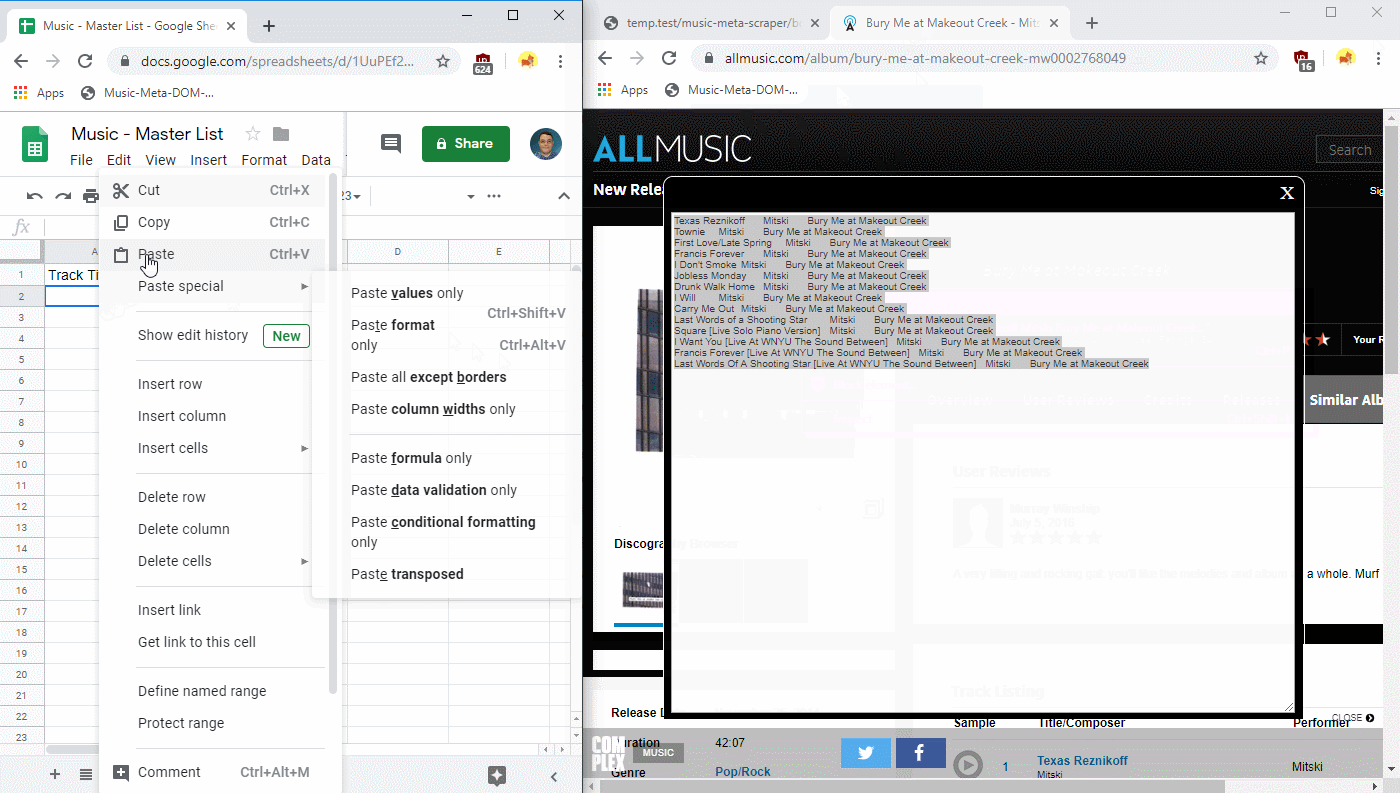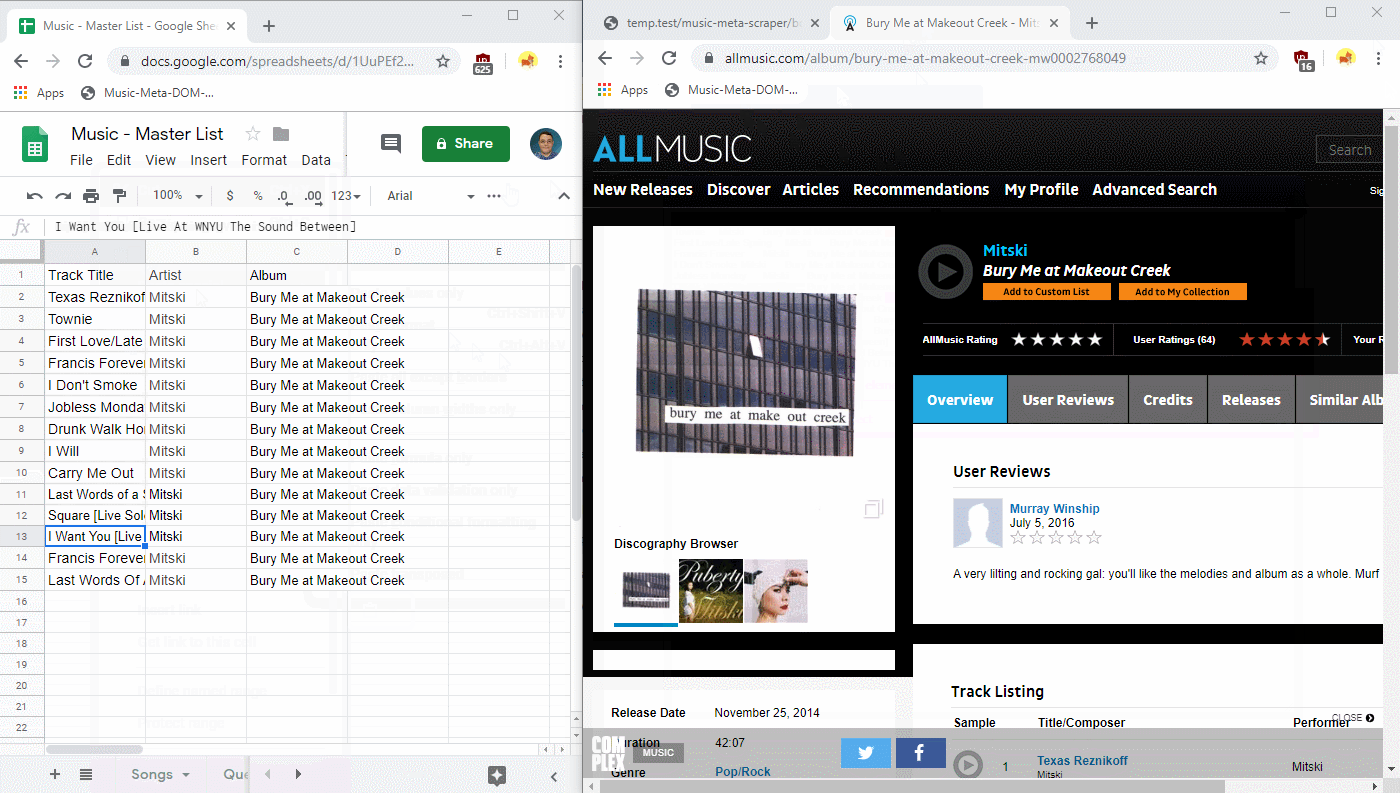
Right now, I have it built as a simple bookmarklet, which you can install below: